Schemathesis: property-based testing for API schemas

Many companies have moved from monoliths to microservices for better scalability and faster development cycles and so have we at Kiwi.com. We still have monolithic applications, however they are melting away over time and a swarm of shiny microservices is gradually replacing them.
These new microservices use Open API schemas to declare their contracts and be explicit in their expectations. Schemas give a lot of benefits like auto-generated clients, interactive documentation and they help to control how applications interact with each other.
Inter-service communication gets more challenging when the number of participants grows and in this article, I would like to share my thoughts on the problems of using schemas in web applications and outline some ways that we can fight against them.
ANNOUNCE: I build a service for API fuzzing. Sign up to check your API now!
Even though Open API is superior to its predecessor, Swagger, it has a lot of limitations as well as any schema specification. The main problem is that even if the declared schema is reflecting everything meant by the author, it doesn’t mean that the actual application conforms to the schema.
There are many different approaches that try to bring schemas, apps, and documentation in sync. The most common approaches are:
- Keep separate, sync manually;
- Generate schema from the application (for example, apispec);
- Provide application logic from the declared schema (connexion).
None of these approaches guarantee a 1:1 match of the application behavior and its schema and there are many reasons for it. It could be a complex database constraint that can’t be expressed in schema syntax or a ubiquitous human factor — either we forgot to update the application to reflect its schema or the other way around.
The consequences of these non-conformance issues are many, from a non-handled error, that crashes the app to security problems that might cause a financial loss.
A straightforward way to approach these problems is to test the applications and setup static linters for schema (like Zally from Zalando), which we do a lot of, but things are getting more complicated when you need to work with hundreds of services of various sizes.
Classic, example-based tests have maintenance costs and take time to be written but they are still crucial to any modern development workflow. We were looking for a cheap and efficient way to find defects in the applications we develop, something that will allow us to test apps, written in any language, require minimum maintenance and will be easy to use.
For this purpose, we decided to explore the applicability of property-based testing (PBT) to Open API schemas. The concept itself is not new. It was first implemented in a Haskell library called QuickCheck by Koen Claessen and John Hughes. Nowadays PBT tools are implemented in the majority of programming languages including Python, our main backend language. In the examples below I am going to use Hypothesis by David R. MacIver.
The point of this approach is to define properties which the code should satisfy and test that the properties hold in a large number of randomly generated cases. Let’s imagine a simple function that takes two numbers and returns their sum and a test for it. Our expectation from this code might be, that the implemented addition holds commutative property:
def add(a, b):
return a + b
def test_add(a, b):
assert add(a, b) == add(b, a)
However, Hypothesis could quickly remind us that commutativity holds only for real numbers:
from hypothesis import strategies as st, given
NUMBERS = st.integers() | st.floats()
@given(a=NUMBERS, b=NUMBERS)
def test_add(a, b):
assert add(a, b) == add(b, a)
# Falsifying example: test_add(a=0, b=nan)
PBT allows developers to find a lot of non-obvious cases when the code doesn’t work as expected, so how can it be applied to API schemas?
It turns out that we expect quite a lot from our applications, they should:
- conform to their schemas;
- not crash on any input, either valid or invalid;
- have response time not exceeding a few hundreds of milliseconds;
Schema conformance could be expanded further:
- Valid input should be accepted, invalid input should be rejected;
- All responses have an expected status code;
- All responses have an expected content-type header.
Even though it is not possible to hold these properties in all cases, these points are still good goals. The schemas themselves are a source of expectation from the app, which makes them fit perfectly with PBT.
First of all, we looked around and found that there is already a Python library for this — swagger-conformance,
but it seemed to be abandoned. We needed support for Open API and more flexibility with strategies for data generation
than swagger-conformance has. We also found a recent library — hypothesis-jsonschema, built by one of the Hypothesis
core developers, Zac Hatfield-Dodds. I am entirely grateful to people who took the time to develop these libraries.
With their efforts, testing in Python has become more exciting, inspiring and enjoyable.
Since Open API is based on JSON Schema it was a close match, but not exactly what we needed.
Having these findings we decided to build our own library on top of Hypothesis, hypothesis-jsonschema and pytest,
which will target the Open API and Swagger specifications.
This is how the Schemathesis project started a few months ago in our Testing Platform team at Kiwi.com. The idea is to:
- Convert Open API & Swagger definitions to JSON Schema;
- Use hypothesis-jsonschema to get proper Hypothesis strategies;
- Use these strategies in CLI & hand-written tests.
It generates test data that conforms to the schema and makes a relevant network call to a running app and checks if it crashes or if the received response conforms to the schema.
We still have a lot of interesting things to implement such as:
- Generating invalid data;
- Schema generation from other specifications;
- Schema generation from WSGI applications;
- Application-side instrumentation for better debugging;
- Targeted data fuzzing based on code coverage or other parameters.
Even now it has helped us to improve our applications and fight against certain classes of defects. Let me show you a few examples of how Schemathesis works and what errors it can find. For this purpose I have created a sample project that implements simple API for bookings, the source code is here — https://github.com/Stranger6667/schemathesis-example. It has defects, that are usually not that obvious from the first glance and we will find them with Schemathesis.
There are two endpoints:
POST /api/bookings— creates a new bookingGET /api/bookings/{booking_id}/— get a booking by ID
For the rest of the article, I assume this project running on 127.0.0.1:8080.
Schemathesis could be used as a command-line application or in Python tests, both options have their own advantages and disadvantages and I will mention them in the next few paragraphs.
Let’s start with CLI and I will try to create a new booking. The booking model has just a few fields, which are described in the following schema and a database table:
components:
schemas:
Booking:
properties:
id:
type: integer
name:
type: string
is_active:
type: boolean
type: object
CREATE TABLE bookings (
id INTEGER PRIMARY KEY,
name VARCHAR(30),
is_active BOOLEAN
);
Handlers & models:
# models.py
import attr
@attr.s(slots=True)
class Booking:
id: int = attr.ib()
name: str = attr.ib()
is_active: bool = attr.ib()
asdict = attr.asdict
# db.py
from . import models
async def create_booking(
pool, *, booking_id: int, name: str, is_active: bool
) -> models.Booking:
row = await pool.fetchrow(
"INSERT INTO bookings (id, name, is_active) VALUES ($1, $2, $3) RETURNING *",
booking_id, name, is_active
)
return models.Booking(**row)
# views.py
from aiohttp import web
from . import db
async def create_booking(request: web.Request, body) -> web.Response:
booking = await db.create_booking(
request.app["db"],
booking_id=body["id"],
name=body["name"],
is_active=body["is_active"]
)
return web.json_response(booking.asdict())
Have you spotted a flaw that might crash the application with an unhandled error?
We need to run Schemathesis against our API’s specific endpoint:
$ schemathesis run
-M POST
-E /bookings/
http://0.0.0.0:8080/api/openapi.json
These two options, --method and --endpoint allow you to run tests only on endpoints that are interesting for you.
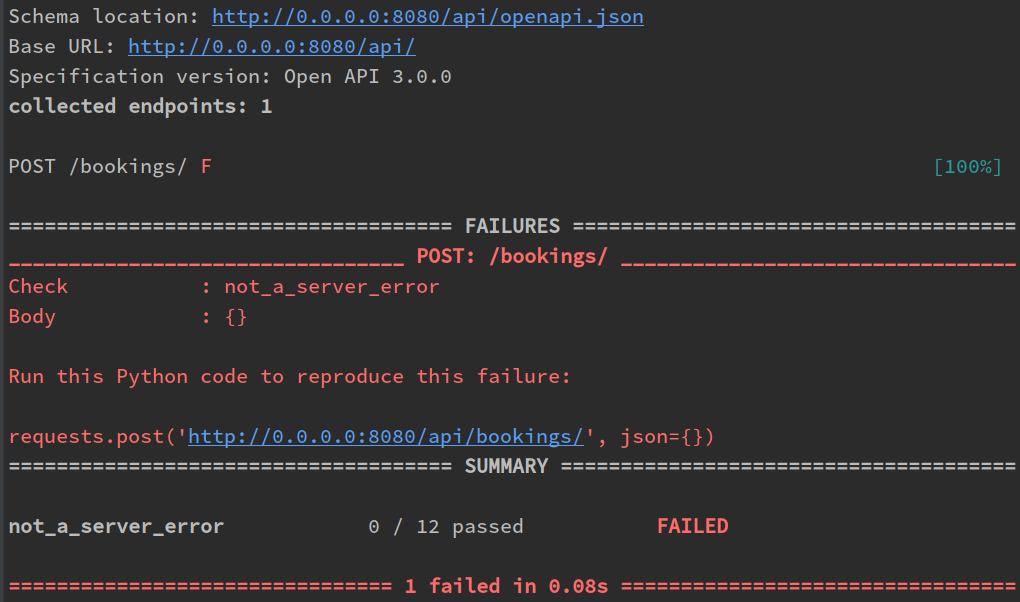
Schemathesis CLI will compose a simple Python code so you can reproduce the error easily and will remember it in the Hypothesis Internal Database, so it will be used in a subsequent run. A traceback in the server output unveils the troublesome parameter:
File "/example/views.py", line 13, in create_booking
request.app["db"], booking_id=body["id"], name=body["name"], is_active=body["is_active"]
KeyError: 'id'
The fix is simple, we need to make id and other parameters required in the schema:
components:
schemas:
Booking:
properties:
id:
type: integer
name:
type: string
is_active:
type: boolean
type: object
required: [id, name, is_active]
Let’s re-run the last command and check if everything is OK:

Again! The exception on the application side:
asyncpg.exceptions.UniqueViolationError: duplicate key value violates unique constraint "bookings_pkey"
DETAIL: Key (id)=(0) already exists.
It seems like I didn’t consider that the user can try to create the same booking twice! However, things like that are common on production — double-clicking, retrying on failure, etc.
We often can’t imagine how our applications will be used after deployment, but PBT can help with discovering what logic is missing in the implementation.
Alternatively, Schemathesis provides a way to integrate its features in the usual Python test suites. The other endpoint may seem straightforward — take an object from the database and serialize it, but it also contains a mistake.
paths:
/bookings/{booking_id}:
parameters:
- description: Booking ID to retrieve
in: path
name: booking_id
required: true
schema:
format: int32
type: integer
get:
summary: Get a booking by ID
operationId: example.views.get_booking_by_id
responses:
"200":
description: OK
# db.py
async def get_booking_by_id(pool, *, booking_id: int) -> Optional[models.Booking]:
row = await pool.fetchrow(
"SELECT * FROM bookings WHERE id = $1", booking_id
)
if row is not None:
return models.Booking(**row)
# views.py
async def get_booking_by_id(request: web.Request, booking_id: int) -> web.Response:
booking = await db.get_booking_by_id(request.app["db"], booking_id=booking_id)
if booking is not None:
data = booking.asdict()
else:
data = {}
return web.json_response(data)
The central element of Schemathesis in-code usage is a schema instance. It provides test parametrization, selecting endpoints to test and other configuration options.
There are multiple ways to create the schema and all of them could be found under schemathesis.from_<something> pattern.
Usually, it is much better to have an application as a pytest fixture, so it could be started on-demand (and schemathesis.from_pytest_fixture will help to make it so),
but for simplicity, I will follow my assumption of the application running locally on 8080 port:
import schemathesis
schema = schemathesis.from_uri("http://0.0.0.0:8080/api/openapi.json")
@schema.parametrize(method="GET", endpoint="/bookings/{booking_id}")
def test_get_booking(case):
response = case.call()
assert response.status_code < 500
Each test with this schema.parametrize decorator should accept a case fixture, that contains attributes required by
the schema and extra information to make a relevant network request. It could look like this:
>>> case
Case(
path='/bookings/{booking_id}',
method='GET',
base_url='http://0.0.0.0:8080/api',
path_parameters={'booking_id': 2147483648},
headers={},
cookies={},
query={},
body=None,
form_data={}
)
Case.call makes a request with this data to the running app via requests.
And the tests could be run with pytest (but unittest from the standard library is supported as well):
$ pytest test_example.py -v
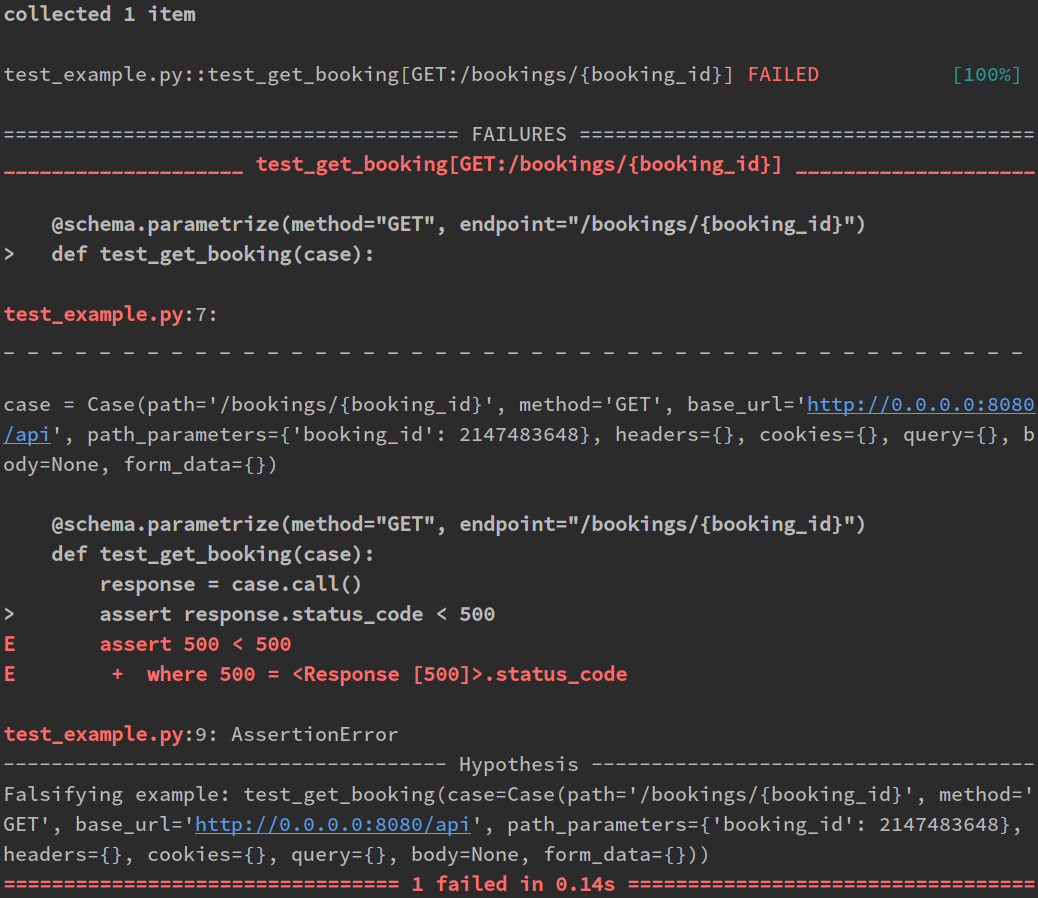
Server-side exception:
asyncpg.exceptions.DataError: invalid input for query argument $1: 2147483648 (value out of int32 range)
The output denotes the problem with lacking input value validation, the fix is to specify proper boundaries for
this parameter in the schema. Having format: int32 is not enough for validating the value, according to the
specification, it is only a hint.
The example application is oversimplified and lacks many properties of production such as authorization, error reporting and so on. Nevertheless, Schemathesis and property-based testing, in general, can discover a wide spectrum of problems in applications. Here is a summary from the above and some more examples:
- Missing logic for non-common scenarios;
- Data corruption (due to lack of validation);
- Denial of service (e.g. due to badly composed regular expressions);
- Errors in client implementations (due to allowing unlisted properties in the input values);
- Other bugs that make the application crash.
These problems have differing severity levels, however, even small crashes clog up your error tracker and appear in your notifications. I have faced some errors like those on production and I prefer to fix them early rather than being awoken by PagerDuty call in the middle of the night!
There are a lot of things to improve these in areas and I would like to encourage you to contribute to Schemathesis, Hypothesis, hypothesis-jsonschema or pytest, they are all open-sourced. You will find a list of links to all these projects below.
Thank you for your attention! :)
Let me know in the Discord chat any feedback or question you might have.
References:
- Apispec — https://github.com/marshmallow-code/apispec
- Connexion — https://github.com/zalando/connexion
- Zally — https://github.com/zalando/zally
- QuickCheck — http://hackage.haskell.org/package/QuickCheck
- Hypothesis — https://github.com/HypothesisWorks/hypothesis
- Swagger-conformance — https://github.com/olipratt/swagger-conformance
- Hypothesis-jsonschema — https://github.com/Zac-HD/hypothesis-jsonschema
- Schemathesis — https://github.com/kiwicom/schemathesis
- Example project — https://github.com/Stranger6667/schemathesis-example
❤ ❤ ❤