Blazingly Fast Linked Lists

Linked lists are taught as fundamental data structures in programming courses, but they are more commonly encountered in tech interviews than in real-world projects.
In this post, I'll demonstrate a practical use case where a linked list significantly outperforms Vec.
We will build a simple data validation library that shows the exact error location within invalid input, showcasing how a linked list can be used in graph traversals.
This post mostly reflects my own exploration and mistakes in the
jsonschemacrates and therefore does not aim to provide a complete guide to linked lists but rather to present an idea of how they can be used in practice.
Starting with a naive approach, we’ll progressively implement various optimizations and observe their impact on performance.
Readers are expected to have a basic understanding of Rust, common data structures, and the concept of memory allocations (stack vs. heap).
UPDATE (2024-05-14): Given the feedback I emphasized what ideas are objectively bad, clarified some sidenotes, and removed the imbl idea.
To follow along with the implementation steps and explore the code, check out the accompanying repository
Validation API
Our library is fairly minimal, and follows JSON Schema semantics:
use serde_json::json;
fn main() -> Result<(), Box<dyn std::error::Error>> {
jsonschema::validate(
// JSON instance to validate
&json!({
"name": "John",
"location": {
"country": 404
}
}),
// JSON schema
&json!({
"properties": {
"name": {
"type": "string"
},
"location": {
"properties": {
"country": {
"type": "string"
}
}
}
}
}),
).expect_err("Should fail");
Ok(())
}
In this example, 404 is not a string and this code should result in an error like this:
404 is not of type ‘string’ at /location/country
| | |
| ---------------
| |
| Location within the JSON instance
|
Failing value
This library and optimization ideas are derived from my jsonschema crate
The validation process boils down to graph traversal. The input instance is traversed based on rules defined in the schema. At any traversal step, we should know the current location within the JSON instance to potentially report a meaningful error.
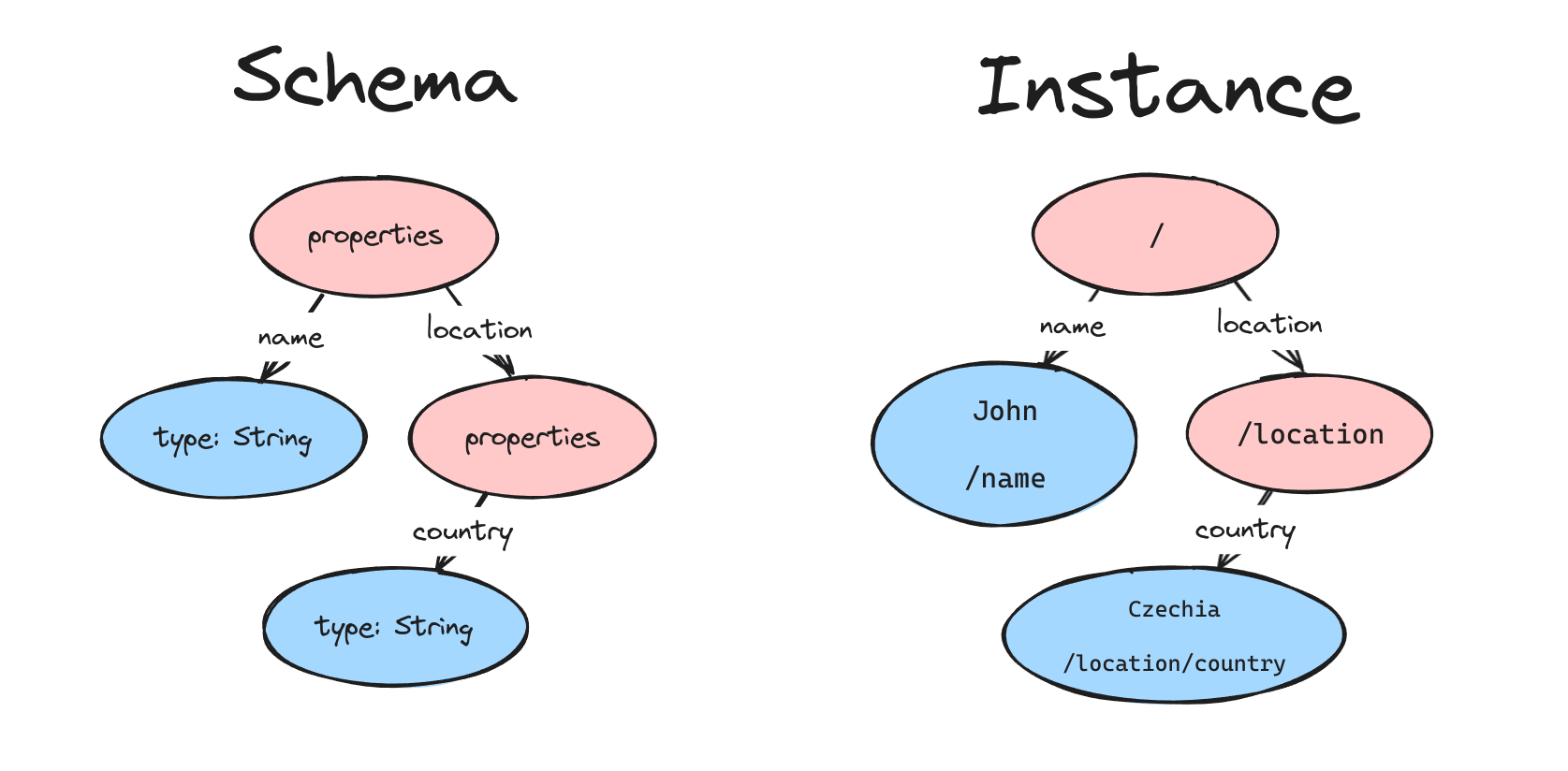
Our primary goal is to implement location tracking while minimizing its impact on the library's performance.
Without diving too deep into the Validator and Node implementations, let's see a simplified version of the validation process without location tracking:
type ValidationResult = Result<(), ValidationError>;
fn validate(instance: &Value, schema: &Value) -> ValidationResult {
Validator::new(schema)
.expect("Invalid schema")
.validate(instance)
}
struct ValidationError {
message: String,
}
impl Validator {
/// Validate JSON instance against this validator.
fn validate(&self, instance: &Value) -> ValidationResult {
self.node.validate(instance)
}
}
trait Node {
fn validate(&self, instance: &Value) -> ValidationResult;
}
impl Node for Properties {
fn validate(&self, instance: &Value) -> ValidationResult {
if let Value::Object(object) = instance {
// Iterate over properties and validate them if they are present.
for (key, value) in &self.properties {
if let Some(instance) = object.get(key) {
// Delegate validation to the child validator.
value.validate(instance)?;
}
}
}
Ok(())
}
}
impl Node for Type {
fn validate(&self, instance: &Value) -> ValidationResult {
// ...
}
}
The validate function creates a new Validator instance (that is also a graph) from the provided schema and then calls its validate method with the JSON instance.
The Node trait defines the validate method that each validation rule must implement.
While this version provides error messages without location tracking, it serves as an upper bound for subsequent optimizations within the validate function.
Benchmark setup
To ensure the optimizations are relevant to the library's typical usage scenarios, we select inputs from different groups - valid and invalid instances of varying sizes.
The schema contains 10 levels of nesting and is deliberately restricted to only the properties and type keywords, which are sufficient to demonstrate the overhead of path-tracking behavior while simplifying benchmarking and keeping our focus on performance rather than JSON Schema semantics. It's worth noting that the path-tracking behavior will remain largely the same for other keywords as well.
{
"properties":{
"another":{
"type":"string"
},
"inner":{
"properties":{
"another":{
"type":"string"
},
"inner":{
"properties":{
// And so on for up to 10 levels
}
}
}
}
}
}
The instances have 0, 5, or 10 levels of nesting, following the schema's structure. Valid instances have a string value for the "another" property at the deepest level, while invalid instances have an integer.
// Valid - 5 levels
{
"inner":{
"inner":{
"inner":{
"inner":{
"another":"hello"
}
}
}
}
}
// Invalid - 5 levels
{
"inner":{
"inner":{
"inner":{
"inner":{
"another":1
}
}
}
}
}
To focus on the performance of the validation process itself, the schema is hardcoded in Validator::new, and Validator is built once and then reused.
Let’s measure performance with criterion by running the following validation routine:
const NUMBER_OF_ITERATIONS: usize = 10000;
fn benchmarks(c: &mut Criterion) {
// snip ...
for instance in &benchmark.instances {
c.bench_with_input(
BenchmarkId::new(instance.kind, &instance.name),
&instance.value,
|b: &mut Bencher, value| {
b.iter(|| {
for _ in 0..NUMBER_OF_ITERATIONS {
let _ = validator.validate(value);
}
});
},
);
}
}
| Commit | Valid | Invalid | ||||
|---|---|---|---|---|---|---|
| 0 | 5 | 10 | 0 | 5 | 10 | |
| a030dcb | 36.3 µs | 553.8 µs | 1.11 ms | 475.2 µs | 914.8 µs | 1.48 ms |
The numbers in these microbenchmarks are not absolute and may vary depending on the hardware and the environment. Generally, the observed changes could be explained by stack traces in flame graphs, but you always need to check the benchmarks yourself.
Bad Idea 1: Clone Vec
Let's start from collecting traversed path segments in a vector adding a new segment each time validation goes one level deeper:
fn validate(&self, instance: &Value) -> ValidationResult {
// Start with an empty vector
self.node.validate(instance, vec![])
}
trait Node {
// Add `path` parameter to track the current location in the JSON instance
fn validate(&self, instance: &Value, path: Vec<&str>) -> ValidationResult;
}
impl Node for Properties {
fn validate(&self, instance: &Value, path: Vec<&str>) -> ValidationResult {
if let Value::Object(object) = instance {
for (key, value) in &self.properties {
if let Some((key, instance)) = object.get_key_value(key) {
// CLONE!
let mut path = path.clone();
path.push(key);
value.validate(instance, path)?;
}
}
}
Ok(())
}
}
impl Node for Type {
fn validate(&self, instance: &Value, path: Vec<&str>) -> ValidationResult {
match (self, instance) {
// ... Compare `instance` type with expected type
_ => Err(ValidationError::new(
format!("{instance} is not of type '{self}'"),
// Convert path to an iterator
path.into_iter(),
)),
}
}
}
The ValidationError struct now stores this path:
struct ValidationError {
message: String,
/// Error location within the input instance.
location: Vec<String>,
}
impl ValidationError {
/// Create new validation error.
fn new(
message: impl Into<String>,
// Accept an iterator and convert it to `Vec<String>`
location: impl Iterator<Item = impl Into<String>>,
) -> Self {
Self {
message: message.into(),
location: location.map(Into::into).collect(),
}
}
}
If you've been writing Rust for a while, you'll likely recognize the clone() call as a common "solution" to lifetime and mutability issues. While it is acceptable in certain situations, depending on your performance and maintainability constraints, it often signals an opportunity for optimization. Let's use such an opportunity here.
| Commit | Valid | Invalid | ||||
|---|---|---|---|---|---|---|
| 0 | 5 | 10 | 0 | 5 | 10 | |
| 9ef7b4c vs Base |
40.9 µs (+12%) |
2.61 ms (+369.4%) |
6.69 ms (+499.6%) |
961.2 µs (+100.8%) |
4.11 ms (+346.8%) |
9.07 ms (+502.7%) |
| Commit |
|---|
| 9ef7b4c vs Base |
| Valid | ||
|---|---|---|
| 0 | 5 | 10 |
| 40.9 µs (+12%) |
2.61 ms (+369.4%) |
6.69 ms (+499.6%) |
| Invalid | ||
|---|---|---|
| 0 | 5 | 10 |
| 961.2 µs (+100.8%) |
4.11 ms (+346.8%) |
9.07 ms (+502.7%) |
This feature makes validation up to 6 times slower!
NOTE: The table compares the current idea with the previous one.
Cloning is generally a bad idea, but it is often seen in practice when developers are doing "quick and dirty" work or not aware about better options. Surely I used it many times.
Let’s visualize the slowest "valid" benchmark using cargo flamegraph to understand what is going on. As expected, the memory reallocations show up in the flame graph:
cargo flamegraph --bench jsonschema -o naive-10.svg -- --bench "^valid/10 levels"
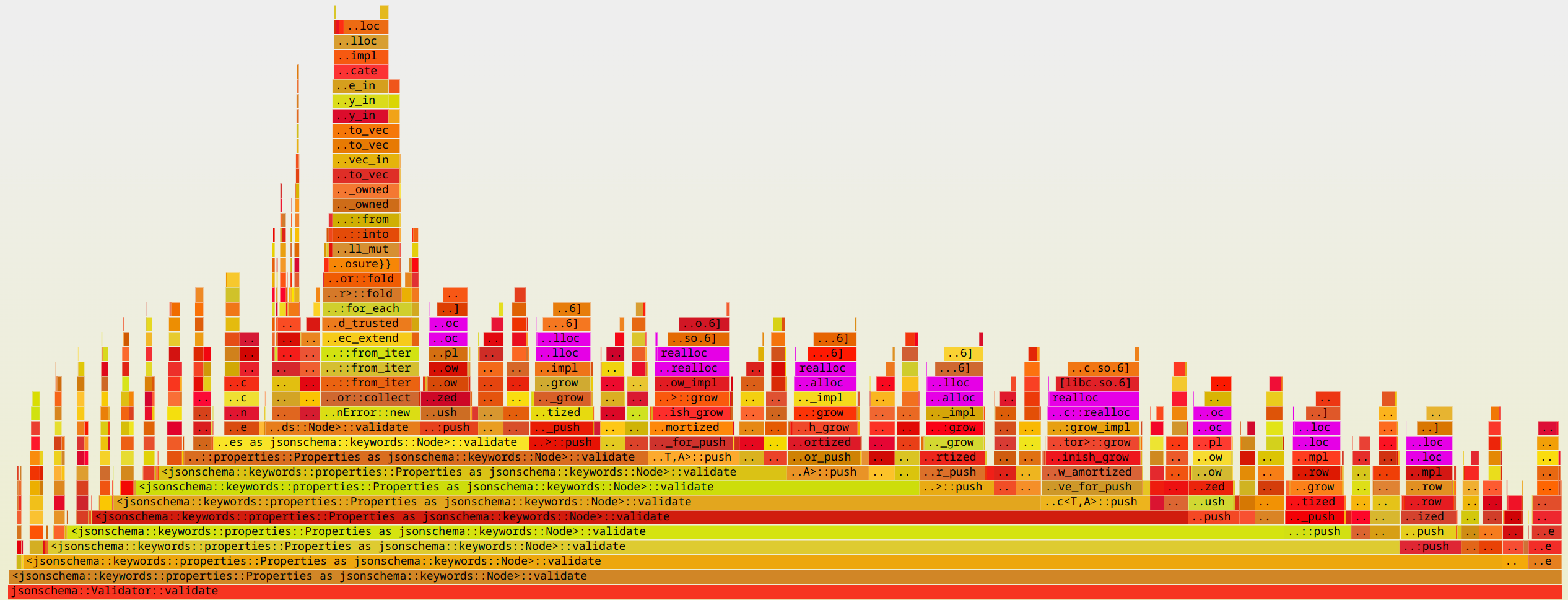
Flame graphs are amazing for visualizing stack traces, see more details here
OK Idea 2: Reuse allocations
However, you may note that we don't have to clone the data - what if we mutate the same vector, pushing and popping segments as we traverse?
trait Node {
fn validate<'a>(
&self,
instance: &'a Value,
path: &mut Vec<&'a str>,
) -> ValidationResult;
}
impl Node for Properties {
fn validate<'a>(
&self,
instance: &'a Value,
path: &mut Vec<&'a str>,
) -> ValidationResult {
// ...
path.push(key);
value.validate(instance, path)?;
path.pop();
// ...
}
}
impl Node for Type {
fn validate<'a>(
&self,
instance: &'a Value,
path: &mut Vec<&'a str>,
) -> ValidationResult {
match (self, instance) {
// ... Compare `instance` type with expected type
_ => Err(ValidationError::new(
format!("{instance} is not of type '{self}'"),
path.iter().copied(),
)),
}
}
The lifetime annotations ('a) are needed here because the path parameter is a mutable reference to a Vec that contains references to the instance parameter. The lifetime 'a ensures that the references in path do not outlive the instance they refer to.
| Commit | Valid | Invalid | ||||
|---|---|---|---|---|---|---|
| 0 | 5 | 10 | 0 | 5 | 10 | |
| 7c94736 vs Idea 1 |
40.2 µs (-1.7%) |
1.24 ms (-110.4%) |
2.46 ms (-171.9%) |
951.7 µs (-1.0%) |
2.39 ms (-71.9%) |
4.16 ms (-118.0%) |
| vs Base | +10.7% | +124.2% | +121.6% | +100.2% | +161.4% | +181.0% |
| Commit |
|---|
| 7c94736 vs Idea 1 vs Base |
| Valid | ||
|---|---|---|
| 0 | 5 | 10 |
| 40.2 µs (-1.7%) |
1.24 ms (-110.4%) |
2.46 ms (-171.9%) |
| +10.7% | +124.2% | +121.6% |
| Invalid | ||
|---|---|---|
| 0 | 5 | 10 |
| 951.7 µs (-1.0%) |
2.39 ms (-71.9%) |
4.16 ms (-118.0%) |
| +100.2% | +161.4% | +181.0% |
Indeed, using &mut Vec can significantly improve performance compared to the naive approach, by reusing a single heap allocation instead of creating multiple clones. However, this approach requires a bit more bookkeeping and somewhat more lifetime annotations.
This is our baseline idea for comparison. This akin to what I originally committed to the
jsonschemacrate.
Better Idea 3: Linked list
However, is it even necessary to allocate heap memory for a vector during traversal? Consider this: for each traversed node in the input value, there's a corresponding validate function call with its own stack frame. As a result, path segments can be stored in these stack frames, eliminating the need for heap allocations completely.
Taking a step back and looking from a different angle can uncover ideas that may not be apparent at a lower level.
By storing all segments on the stack, when an error happens, the previous segments can be traced back. This approach involves connecting each segment to form a path and collecting them when necessary. This sounds like a linked list:
/// A node in a linked list representing a JSON pointer.
struct JsonPointerNode<'a, 'b> {
segment: Option<&'a str>,
parent: Option<&'b JsonPointerNode<'a, 'b>>,
}
impl<'a, 'b> JsonPointerNode<'a, 'b> {
/// Create a root node of a JSON pointer.
const fn new() -> Self {
JsonPointerNode {
segment: None,
parent: None,
}
}
/// Push a new segment to the JSON pointer.
fn push(&'a self, segment: &'a str) -> JsonPointerNode<'a, 'b> {
JsonPointerNode {
segment: Some(segment),
parent: Some(self),
}
}
/// Convert the JSON pointer node to a vector of path segments.
fn to_vec(&'a self) -> Vec<&'a str> {
// Callect the segments from the head to the tail
let mut buffer = Vec::new();
let mut head = self;
if let Some(segment) = &head.segment {
buffer.push(*segment);
}
while let Some(next) = head.parent {
head = next;
if let Some(segment) = &head.segment {
buffer.push(*segment);
}
}
// Reverse the buffer to get the segments in the correct order
buffer.reverse();
buffer
}
}
Now we can replace &mut Vec:
fn validate(&self, instance: &Value) -> ValidationResult {
self.node.validate(instance, JsonPointerNode::new())
}
trait Node {
fn validate<'a>(
&self,
instance: &'a Value,
path: JsonPointerNode<'a, '_>,
) -> ValidationResult;
}
impl Node for Properties {
fn validate<'a>(
&self,
instance: &'a Value,
path: JsonPointerNode<'a, '_>,
) -> ValidationResult {
// ...
value.validate(instance, path.push(key.as_str()))?;
// ...
}
impl Node for Type {
fn validate<'a>(
&self,
instance: &'a Value,
path: JsonPointerNode<'a, '_>,
) -> ValidationResult {
match (self, instance) {
// ... Compare `instance` type with expected type
_ => Err(ValidationError::new(
format!("{instance} is not of type '{self}'"),
path.to_vec().into_iter(),
)),
}
}
}
No heap allocations during traversal! Does it help?
| Commit | Valid | Invalid | ||||
|---|---|---|---|---|---|---|
| 0 | 5 | 10 | 0 | 5 | 10 | |
| 91ec92c vs Idea 2 |
35.0 µs (-14.8%) |
663.5 µs (-46.4%) |
1.32 ms (-46.6%) |
958.9 µs (+1.8%) |
2.54 ms (+5.1%) |
4.58 ms (+9.9%) |
| Commit |
|---|
| 91ec92c vs Idea 2 |
| Valid | ||
|---|---|---|
| 0 | 5 | 10 |
| 35.0 µs (-14.8%) |
663.5 µs (-46.4%) |
1.32 ms (-46.6%) |
| Invalid | ||
|---|---|---|
| 0 | 5 | 10 |
| 958.9 µs (+1.8%) |
2.54 ms (+5.1%) |
4.58 ms (+9.9%) |
Woah! That is significantly better for valid inputs! Invalid ones are roughly the same, however, we have not optimized the linked list implementation yet.
In our case, we are leveraging the fact, that the path is only needed when an error occurs. This allows us to avoid the overhead of maintaining the path during the entire traversal process and heap allocate only when necessary.
Note that linked lists have worse cache locality compared to vectors, which can lead to slower performance in some scenarios.
Good Idea 4: Precise memory allocation
Let's find out why the linked list implementation is not as performant for invalid inputs by looking at JsonPointerNode first:
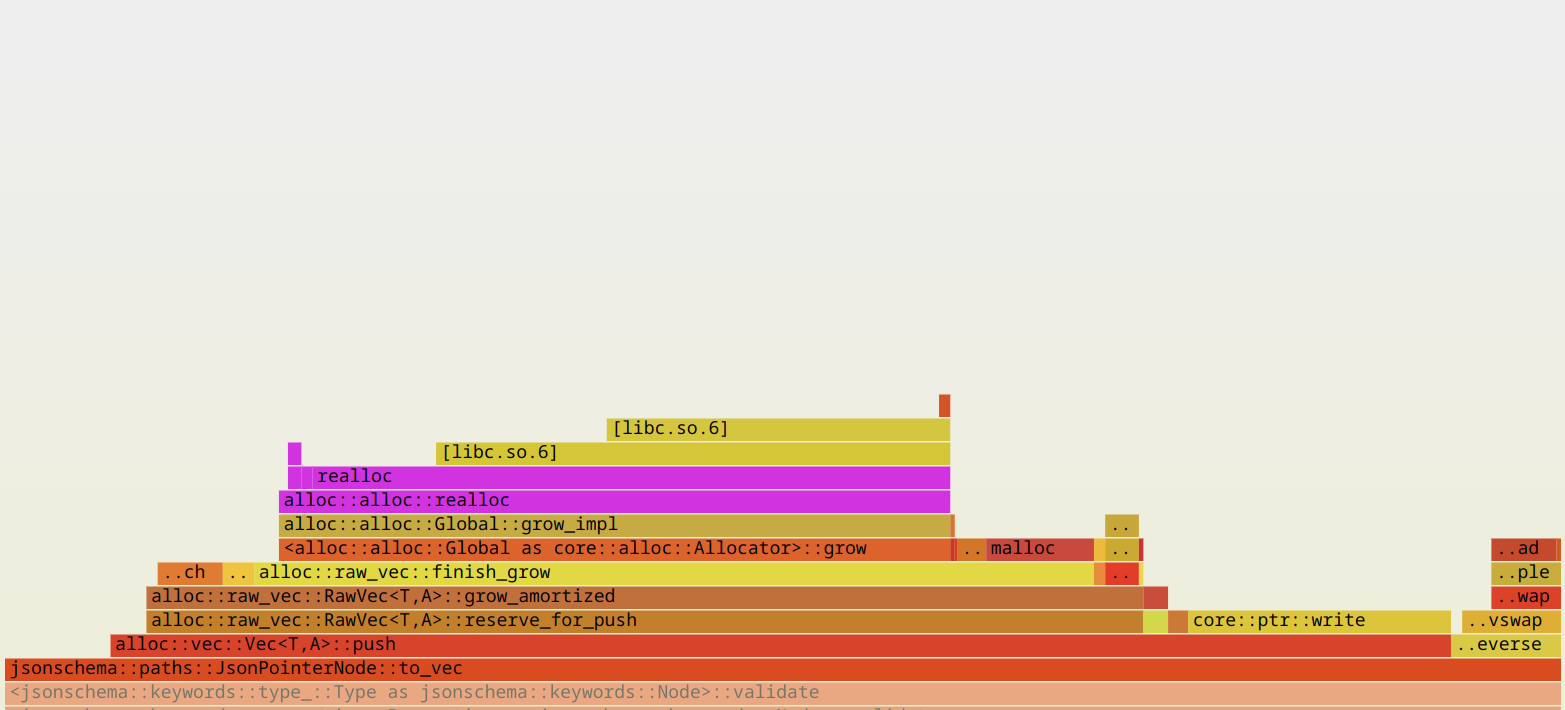
Apparently, the problem is in memory reallocations inside JsonPointerNode::to_vec. We can avoid them by allocating the exact amount of memory needed. This will require an extra linked list traversal to calculate the capacity, but the performance gain from avoiding reallocations outweighs the cost of the extra traversal:
impl<'a, 'b> JsonPointerNode<'a, 'b> {
pub(crate) fn to_vec(&'a self) -> Vec<&'a str> {
// Walk the linked list to calculate the capacity
let mut capacity = 0;
let mut head = self;
while let Some(next) = head.parent {
head = next;
capacity += 1;
}
// Callect the segments from the head to the tail
let mut buffer = Vec::with_capacity(capacity);
let mut head = self;
if let Some(segment) = &head.segment {
buffer.push(*segment);
}
while let Some(next) = head.parent {
head = next;
if let Some(segment) = &head.segment {
buffer.push(*segment);
}
}
// Reverse the buffer to get the segments in the correct order
buffer.reverse();
buffer
}
}
| Commit | Valid | Invalid | ||||
|---|---|---|---|---|---|---|
| 0 | 5 | 10 | 0 | 5 | 10 | |
| 10ae4f1 vs Idea 3 |
39.1 µs (+11.2%) |
667.9 µs (+0.5%) |
1.30 ms (-1.7%) |
899.7 µs (-7.5%) |
1.96 ms (-23.3%) |
3.49 ms (-24.3%) |
| Commit |
|---|
| 10ae4f1 vs Idea 3 |
| Valid | ||
|---|---|---|
| 0 | 5 | 10 |
| 39.1 µs (+11.2%) |
667.9 µs (+0.5%) |
1.30 ms (-1.7%) |
| Invalid | ||
|---|---|---|
| 0 | 5 | 10 |
| 899.7 µs (-7.5%) |
1.96 ms (-23.3%) |
3.49 ms (-24.3%) |
Great! Precise memory allocation improves performance for invalid inputs, bringing it closer to the performance of valid ones. Allocate exactly as needed, whenever possible, to avoid the overhead of memory reallocations.
Good Idea 5: Avoid temporary Vec
At this point, the most significant slowdown is for invalid cases. If we take a closer look at the ValidationError implementation we’ll see the collect call, which means that first, we build Vec<&str> in JsonPointerNode::to_vec and then almost immediately build Vec<String> from it, which means allocating Vec twice. Why don’t we just build Vec<String> in the first place:
impl ValidationError {
fn new(message: impl Into<String>, location: Vec<String>) -> Self {
Self {
message: message.into(),
location,
}
}
}
impl Node for Type {
fn validate<'a>(
&self,
instance: &'a Value,
path: JsonPointerNode<'a, '_>,
) -> ValidationResult {
match (self, instance) {
// ... Compare `instance` type with expected type
_ => Err(ValidationError::new(
format!("{instance} is not of type '{self}'"),
path.to_vec(),
)),
}
}
}
impl<'a, 'b> JsonPointerNode<'a, 'b> {
pub(crate) fn to_vec(&self) -> Vec<String> {
// ...
if let Some(segment) = &head.segment {
buffer.push((*segment).to_string());
}
while let Some(next) = head.parent {
head = next;
if let Some(segment) = &head.segment {
buffer.push((*segment).to_string());
}
}
// ...
}
}
This optimization leads to a visible performance improvement for invalid cases:
| Commit | Valid | Invalid | ||||
|---|---|---|---|---|---|---|
| 0 | 5 | 10 | 0 | 5 | 10 | |
| d3d2182 vs Idea 4 |
39.7 µs (-0.2%) |
652.3 µs (-2.7%) |
1.35 ms (+2.2%) |
765.1 µs (-14.2%) |
1.83 ms (-6.9%) |
3.33 ms (-5.9%) |
| Commit |
|---|
| d3d2182 vs Idea 4 |
| Valid | ||
|---|---|---|
| 0 | 5 | 10 |
| 39.7 µs (-0.2%) |
652.3 µs (-2.7%) |
1.35 ms (+2.2%) |
| Invalid | ||
|---|---|---|
| 0 | 5 | 10 |
| 765.1 µs (-14.2%) |
1.83 ms (-6.9%) |
3.33 ms (-5.9%) |
Maybe Good Idea 6: Struct size optimization
Sometimes it is worth trying to reduce struct sizes, especially when the struct is passed by value frequently. Smaller structs lead to less memory usage and faster function calls, as less data needs to be copied on the stack.
If we were to track not only keys in JSON objects but also indexes in arrays, we would need to use an enum like this:
enum Segment<'a> {
/// Property name within a JSON object.
Property(&'a str),
/// Index within a JSON array.
Index(usize),
}
struct JsonPointerNode<'a, 'b> {
segment: Option<Segment<'a>>,
parent: Option<&'b JsonPointerNode<'a, 'b>>,
}
Then, the JsonPointerNode struct would occupy 32 bytes:
assert_eq!(std::mem::size_of::<JsonPointerNode>(), 32);
However, by avoiding Option in the segment field, we can reduce its size to 24 bytes. The idea is to put some cheap value in the root node and never read it:
struct JsonPointerNode<'a, 'b> {
segment: Segment<'a>,
parent: Option<&'b JsonPointerNode<'a, 'b>>,
}
impl<'a, 'b> JsonPointerNode<'a, 'b> {
/// Create a root node of a JSON pointer.
const fn new() -> Self {
JsonPointerNode {
// The value does not matter, it will never be used
segment: Segment::Index(0),
parent: None,
}
}
fn push(&'a self, segment: Segment<'a>) -> JsonPointerNode<'a, 'b> {
JsonPointerNode {
segment,
parent: Some(self),
}
}
/// Convert the JSON pointer node to a vector of path segments.
pub(crate) fn to_vec(&self) -> Vec<String> {
// ...
if head.parent.is_some() {
buffer.push(head.segment.to_string())
}
while let Some(next) = head.parent {
head = next;
if head.parent.is_some() {
buffer.push(head.segment.to_string());
}
}
// ...
}
}
This technique is directly used in the jsonschema crate to reduce the size of the JsonPointerNode struct, but not used here for simplicity.
More ideas that didn't make it
I think that we can also gain a bit more performance by avoiding the reverse call in JsonPointerNode::to_vec, as it moves the data around. One way to achieve this is by assigning segments starting from the back of a vector filled with default values. However, the extra bookeeping needed for writing in the reverse order could outweigh the gains, so it's important to profile and benchmark any changes to ensure they provide measurable benefits for your use case.
Another idea is to store references to path segments inside ValidationError instead of cloning the strings:
struct ValidationError<'a> {
message: String,
location: Vec<&'a str>,
}
This way, we can avoid cloning the path segments and instead store references to them. This could lead to performance improvements, especially when dealing with long paths or large numbers of errors. However, this approach would make ValidationError less flexible, as it would be tied to the lifetime of the input JSON data.
Excellent Idea 7: Maybe you don't need a linked list?
This idea was suggested by @Kobzol, who noted that the error path could be collected lazily from the call stack in the error propagation path. I've implemented the idea based on the suggestion and the original code snippet:
impl ValidationError {
pub(crate) fn push_segment(&mut self, segment: String) {
self.location.push(segment);
}
pub(crate) fn finish(mut self) -> ValidationError {
self.location.reverse();
self
}
}
fn validate(&self, instance: &Value) -> ValidationResult {
if let Err(error) = self.node.validate(instance, 0) {
// Reverse the path segments in the `finish` method
Err(error.finish())
} else {
Ok(())
}
}
impl Node for Properties {
fn validate(&self, instance: &Value, level: u32) -> ValidationResult {
// ...
for (key, value) in &self.properties {
if let Some(instance) = object.get(key) {
if let Err(mut error) = value.validate(instance, level + 1) {
error.push_segment(key.to_string());
return Err(error);
// ...
}
}
impl Node for Type {
fn validate(&self, instance: &'a Value, level: u32) -> ValidationResult {
// ...
_ => Err(ValidationError::new(
format!("{instance} is not of type '{self}'"),
Vec::with_capacity(level as usize)
// ...
}
}
However, I was not able to get a stable improvement in benchmarks yet :(
Small improvement may come from the fact that we no longer use the
?operator as it involves theFrom/Intoconversion, but we only have a single error type and don't need to convert it. This is the reason whyserdehas its owntri!macro that is used instead of?;
Conclusion
In the end, we achieved ~1.9x / ~1.3x improvements from the baseline implementation for valid / invalid scenarios. Overall this feature adds 18% / 95% on top of the path-less version!
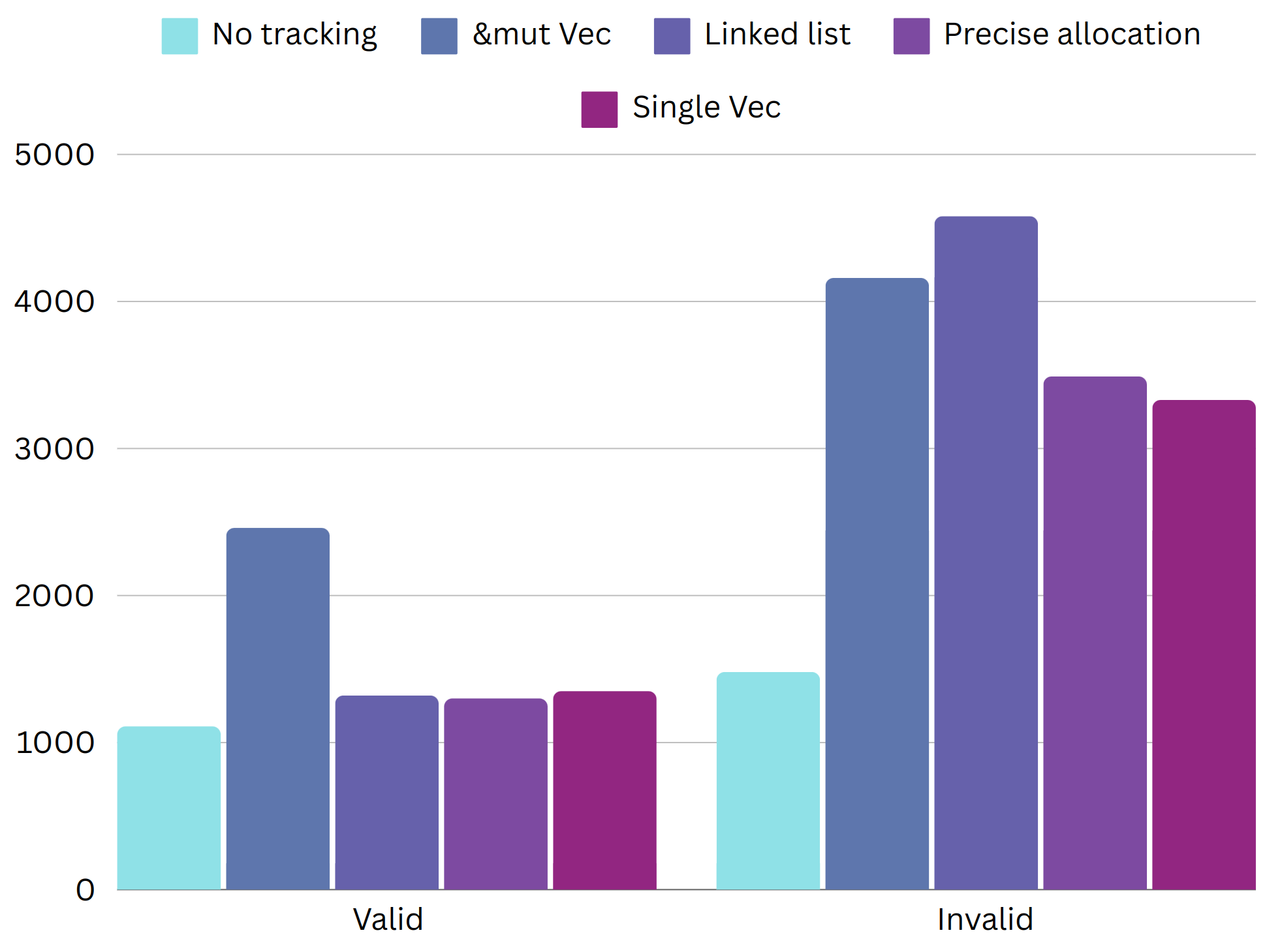
Some optimizations in this article may not seem immediately beneficial, especially if you already know where the bottlenecks are. However, exploring simpler optimizations can sometimes reveal unexpected opportunities for improvement. Even if an optimization doesn't directly pay off or even makes your code slower in some cases, it may open up new possibilities for further optimizations.
Takeaways:
- A naive approach could be good enough
- Look at the problem at different scales
- Search for a data structure that fits your problem
- Allocate exactly as needed and when necessary
- Reduce the size of values you pass around a lot
- Don't use "Blazingly fast" in your post titles
If you have any more ideas to improve this use case or have any suggestions, please let me know!
In the next article, I will dive into HTML trees and why you should try to build your own data structure for it.
Thank you for your attention!
Dmitry